
Originally this blog was built from a Pelican boilerplate. Why? No clue. I must have been looking for something free and fast that would plug right into the rest of my work. It does let me generate a blog site from markdown formatted post files which is an excellent feature I enjoy and want to keep. Coming back to this blog, I wanted to start making modifications to it, but everything about how it was built was buried in imported libraries. When I felt blocked on modifying the site, I decided to rewrite it because I'm an adult who can do what I want.
Assessing the Damage Legacy
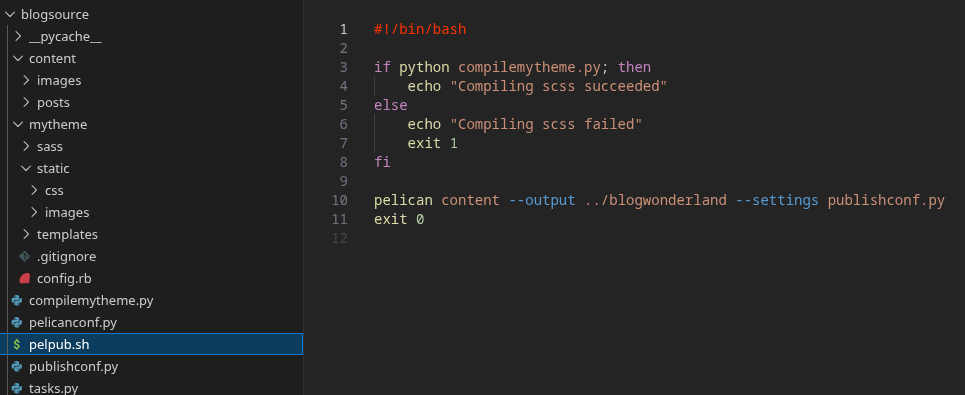
This Pelican project smelled rotten. Several files here config.rb, peliconconf.py, publishconf.py, and tasks.py and parts of Pelican that I would need to learn Pelican specifically to understand. This file structure hardly makes sense to me. That folder structure is needlessly complex. Image and post folders don't need to be in an extra layer, not until there are so many folders that it becomes unwieldy. I hate that I used to create folders left and right like I was still maintaining Java EE 8. But I can't even touch the folder structure because Pelican assumes it. That makes sense for a more complex multi-author blog. For this scope, utterly disgusting.

I had made this build script for myself, poorly named, that compiled scss for reasons unknown before making an opaque blog building call. I wish I had left myself a comment, but I'm 99% sure the scss compile was just for better error visibility and stopping the build when it fails. I am sure when I was editing the scss, I had an issue and added this to speed up iteration fixing the issue. I do have a questionable tendency to do that before fixing issues themselves, adding build complexity in response to pain points as I go.
What does the Pelican call do? It produces the built blog static site folder. How? Hell if I know. Will I learn Pelican to do everything I want in its configuration? Haha no. The project plan is now to replace that line with my own python script. Surely I can move files, build scss, parse markdown, convert markdown to html, and apply parameters to templates. Estimate 1 day.
Needlessly Destroying Water Just In Case
I tried prompting Copilot. It gave me over a thousand lines of a python script in a single code review featuring classes like BlogPost, Category, and BlogBuilder. It built several layers of abstraction and complexity for requirements I didn't give it and for requirements I explained that I don't have. It looked like it might just work, but it failed. Repeatedly. After a few iterations of explaining the error to it, the complexity got worse, and the early errors start circling back again.
That is not giving me code I can maintain in the future myself even if it did eventually get to the point of working. Alternatively, the time it would take for me to write up a sufficiently massive specification to get the correct result would take longer than doing it myself with no LLM. The copilot chat got closed for the day. I swear juniors hyping this shit are telling on themselves. Apologies to Mother Earth for the water I evaporated for that experiment.

The handmade Pelican replacement
Here is the python script that processes my blog "source" folder (its own directory) to build a blog "output" folder:
# buildaliceblog.python
import os
import sys
import re
import errno
import html
from datetime import datetime, timezone
import shutil
import markdown
import sass
from jinja2 import Environment, FileSystemLoader
from feedgen.feed import FeedGenerator
jinja2 = Environment(loader=FileSystemLoader('templates'))
index_template = jinja2.get_template('index.html')
article_template = jinja2.get_template('article.html')
category_template = jinja2.get_template('category.html')
md = markdown.Markdown(
extensions=[
'extra', # Tables, footnotes, etc.
'codehilite', # Syntax highlighting
'toc' # Table of Contents support
]
)
OUT_DIR = '../blogwonderland/'
AUTHOR_NAME = 'Alice Aisly Valente'
DOMAIN_NAME = 'https://blog.wonderlandportfol.io'
BASE_CONFIG = {
'SITENAME': 'Alice in Clouds',
'AUTHOR': 'Alice Aisly Valente',
'DOMAIN_NAME': DOMAIN_NAME,
'FAVICON_FILENAME': 'favicon.ico',
'THEME_STATIC_DIR': 'theme',
'CSS_FILE': 'main.css',
'SITESUBTITLE': 'Writing about technology I play with in the rain because I can',
'FEED_ATOM': 'feeds/all.atom.xml',
'FEED_RSS': 'feeds/all.rss.xml',
}
INDEX_PAGE_SIZE = 10
CATEGORY_PAGE_SIZE = 25
def writeFile(inFileName, inFileData):
if not os.path.exists(os.path.dirname(inFileName)):
try:
os.makedirs(os.path.dirname(inFileName))
except OSError as exc: # Guard against race condition
if exc.errno != errno.EEXIST:
raise
with open(inFileName, "w") as writer:
writer.write(inFileData)
def estimate_reading_time(html_content: str) -> str:
pattern = r'<(?:p|h1|h2)(?:\s[^>]*)?>(.+?)</(?:p|h1|h2)>'
matches = re.findall(pattern, html_content, re.DOTALL)
texts = [html.unescape(re.sub(r'<[^>]+>', '', match).strip()) for match in matches]
total_words = sum(len(text.split()) for text in texts)
return f"{str(total_words // 300)} - {str(total_words // 200)} minutes"
os.makedirs(OUT_DIR + 'images', exist_ok=True)
os.makedirs(OUT_DIR + 'theme/css', exist_ok=True)
os.makedirs(OUT_DIR + 'theme/fonts', exist_ok=True)
os.makedirs(OUT_DIR + 'theme/images', exist_ok=True)
os.makedirs(OUT_DIR + 'category', exist_ok=True)
os.makedirs(OUT_DIR + 'feeds', exist_ok=True)
shutil.copytree('images', OUT_DIR + 'images', dirs_exist_ok=True)
shutil.copytree('fonts', OUT_DIR + 'theme/fonts', dirs_exist_ok=True)
try:
cssStr = sass.compile(filename="sass/main.scss", output_style='compressed')
writeFile(OUT_DIR + "theme/css/main.css", cssStr)
print("Compiling scss succeeded")
except Exception as e:
print(f"Error: {e}", file=sys.stderr)
print("Compiling scss failed")
articles = []
categories = set()
for article_filename in os.listdir('posts/'):
if article_filename.endswith('.markdown'):
article_object = {}
article_rows = []
first_empty_row_index = -1
second_empty_row_index = -1
with open(os.path.join('posts/', article_filename), 'r') as f:
article_rows = f.readlines()
for i, row in enumerate(article_rows):
if row.strip() == '':
if first_empty_row_index == -1:
first_empty_row_index = i
elif second_empty_row_index == -1:
second_empty_row_index = i
break
for i in range(first_empty_row_index):
key_value = article_rows[i].split(': ', 1)
article_object[key_value[0]] = key_value[1].strip()
article_summary_md = ""
for i in range(first_empty_row_index + 1, second_empty_row_index):
article_summary_md += article_rows[i] + '\n'
article_content_md = ""
for i in range(first_empty_row_index + 1, len(article_rows)):
article_content_md += article_rows[i] + '\n'
article_content_html = md.convert(article_content_md)
# I can extend markdown here :)
article_object['content'] = article_content_html
article_summary_html = md.convert(article_summary_md)
article_object['summary'] = article_summary_html
article_object['slug'] = article_filename.replace('.markdown', '')
article_object['category_url'] = f"category/{article_object['category'].replace(' ', '-').lower()}"
article_object['reading_time'] = estimate_reading_time(article_content_html)
articles.append(article_object)
categories.add(article_object['category'])
print(f"{len(articles)} articles found")
print(f"{len(categories)} categories found")
sinceYear: int = 40000
toYear: int = 1970
for article in articles:
year: int = int(article['date'].split('-')[0])
if year < sinceYear:
sinceYear = year
if year > toYear:
toYear = year
article['date'] = datetime.strptime(article['date'], '%Y-%m-%d').date()
article['datetime'] = datetime.combine(article['date'], datetime.min.time()).replace(tzinfo=timezone.utc)
article['url'] = article['slug']
articles.sort(key=lambda x: x['date'], reverse=True)
print(f"Articles found from {sinceYear} to {toYear}")
ARTICLES_CONFIG = {
'articles': articles,
'sinceYear': sinceYear,
'toYear': toYear
}
for page in range(len(articles) // INDEX_PAGE_SIZE + 1):
print(f"Building index page {page + 1}")
page_number = page + 1
html_output = index_template.render({
**BASE_CONFIG,
**ARTICLES_CONFIG,
'current_page_articles': articles[page * INDEX_PAGE_SIZE:(page + 1) * INDEX_PAGE_SIZE],
'previous_page_exists': page_number > 1,
'next_page_exists': (page + 1) * INDEX_PAGE_SIZE < len(articles),
'previous_page_url': f'index-page{page_number - 1}' if page_number > 2 else '',
'next_page_url': f'index-page{page_number + 1}',
})
if page_number == 1:
output_filename = 'index.html'
else:
output_filename = f'index-page{page_number}.html'
writeFile(OUT_DIR + output_filename, html_output)
for article in articles:
print("Building article: " + article['title'])
html_output = article_template.render({
**BASE_CONFIG,
**ARTICLES_CONFIG,
'article': article,
})
output_filename = article['slug'] + '.html'
writeFile(OUT_DIR + output_filename, html_output)
for category in categories:
print(f"Building category page for {category}")
category_articles = [a for a in articles if a['category'] == category]
for page in range(len(articles) // CATEGORY_PAGE_SIZE + 1):
print(f"Building category page {page + 1}")
page_number = page + 1
safe_category = category.replace(" ", "-").lower()
html_output = category_template.render({
**BASE_CONFIG,
**ARTICLES_CONFIG,
'CATEGORY_FEED_RSS': f'feeds/{safe_category}.rss.xml',
'CATEGORY_FEED_ATOM': f'feeds/{safe_category}.atom.xml',
'category': category,
'current_page_articles': category_articles[page * CATEGORY_PAGE_SIZE:(page + 1) * CATEGORY_PAGE_SIZE],
'previous_page_exists': page_number > 1,
'next_page_exists': (page + 1) * CATEGORY_PAGE_SIZE < len(category_articles),
'previous_page_url': f'index-page{page_number - 1}' if page_number > 2 else '',
'next_page_url': f'index-page{page_number + 1}',
})
if page_number > 1:
output_filename = f'category/{safe_category}-page{page_number}.html'
else:
output_filename = f'category/{safe_category}.html'
writeFile(OUT_DIR + output_filename, html_output)
fg = FeedGenerator()
fg.title(BASE_CONFIG['SITENAME'])
fg.link(href=DOMAIN_NAME, rel='alternate')
fg.description(f"Latest posts from {BASE_CONFIG['SITENAME']}")
fg.id(DOMAIN_NAME)
for article in articles[:20]:
fe = fg.add_entry()
fe.title(article['title'])
fe.link(href=f"{DOMAIN_NAME}/{article['slug']}.html")
fe.author( {'name': AUTHOR_NAME} )
fe.pubDate(article['datetime'])
fe.description(article['summary'])
fe.id(f"{DOMAIN_NAME}/{article['slug']}.html")
fg.rss_file(OUT_DIR + 'feeds/all.rss.xml')
fg.atom_file(OUT_DIR + 'feeds/all.atom.xml')
for category in categories:
fg = FeedGenerator()
fg.title(f"{BASE_CONFIG['SITENAME']} - {category}")
fg.link(href=DOMAIN_NAME, rel='alternate')
fg.description(f"Latest posts on {category} from {BASE_CONFIG['SITENAME']}")
fg.id(DOMAIN_NAME)
category_articles = [a for a in articles if a['category'] == category]
for article in category_articles[:20]:
fe = fg.add_entry()
fe.title(article['title'])
fe.link(href=f"{DOMAIN_NAME}/{article['slug']}.html")
fe.author( {'name': AUTHOR_NAME} )
fe.pubDate(article['datetime'])
fe.description(article['summary'])
fe.id(f"{DOMAIN_NAME}/{article['slug']}.html")
safe_category = category.replace(" ", "-").lower()
fg.rss_file(OUT_DIR + f'feeds/{safe_category}.rss.xml')
fg.atom_file(OUT_DIR + f'feeds/{safe_category}.atom.xml')
Under 230 lines of Python does everything, and lets me easily expand on any minor detail of the functionality. I can even expand the markdown pages to include any functionality in any format I want since I am parsing them in my own code. This code may look messy, but look more closely: Ctrl+F will efficiently take me right to where I need to make a change, and all the code is what I consider easily grokable.
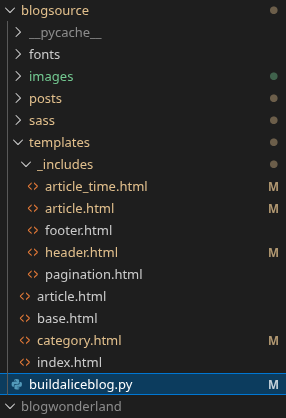
Even better, the templates themselves got much simpler, and now I feel like I can genuinely read them and grok them. I was so lost in these files originally. I removed all the Pelican related files. I made the folder structure simpler. I removed functionality that had been built into Pelican that I do not need. Now the project is far simpler.
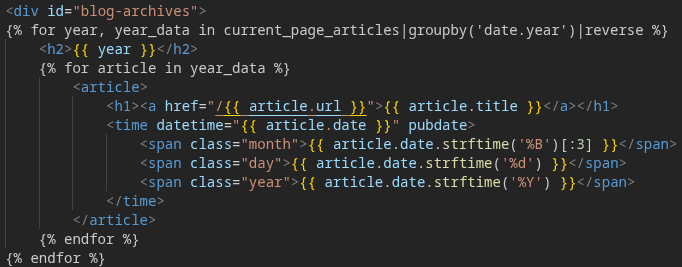
I learned some neat things about Jinja2 templates (something more appealing for me to learn about than Pelican). I think I appreciate them more now, especially their elegance. They have the depth to enable categorizing and sorting lists to then iterate over with such simple syntax for what is being done. There is wiggle room here to decide how much complexity lives in Python versus how much lives in templates. My gut said to divide the complexity rather than consolidate it. I stuck with python building simple data structures like this dated article list, while the template handles sorting them for display.
I did in fact accomplish this "rebuild" in a single day as I thought I would. This was in fact an easy fast task; Writing this blog post took more time. This effort was done without a LLM. This is fundamentally not the kind of task that an engineer can speed up by delegating to a LLM. It doesn't even have components complex enough to warrant delegating. If anything, this is so simple I should have thought to DIY from the start years ago.
About that "clean code"
I think most software engineers greatly overvalue clean code while they undervalue simplicity and robustness. Years of working on legacy systems followed by years of shiny new systems has shattered my illusions. I no longer believe in abstractions that add additional hopping around files to answer a question about how a piece works. I know longer believe in future proofing code rather than pushing what is needed today.
I have faith that I can maintain buildaliceblog.py. That is to say if I come back to this years from now with no recollection of making it and have an unexpected change I want to make, I will be able to make that change quickly. It will not be a nightmare just because there is no AbstractPostPageFactoryBuilderManagerImpl. I will be fine. If anything, more code is more surface area for problems I don't want to have.
I actually managed to make some changes quickly, including adding a profile picture, RSS and ATOM feed links, and estimated reading times from word counts. Now that the blog generation is not an opaque black box, I am rapidly making changes without friction. I am looking forward to the day when my future self decides to redo the UI now rather than dreading it.
The love of building
I could have steered in a more sane direction towards a blog solution that is even more hands off to just create a blog from posts. But I wanted my own little custom blog solution for the sake of having it. If only to have something unique, just for me, that I can fiddle with all I want. I enjoyed building this script immensely. It was extremely satisfying seeing it come together and finally tweaking original files to a much simpler state.
This was not a learning project, not foremost, and certainly not a genuinely productive project producing value. This was hobby time. I was playing a game in vscode and linux terminals. These kinds of building breaks remind me why I am putting so much sweat and tears into this sometimes miserable, often intense career.
I imagine this all looks quite goofy to some engineers. At my first job, the head of R&D would have called this homemade blog framework "Mickey Mouse shit". That is fine by me. If the scope of this blog was larger with more contributors, I would have kept the original author pages, but there would still be no reason to balloon the code with classes upon classes, or write tests for an isolated internal script. At most I would have defined three or four more functions including __main__. This gets work done faster, and feels far more fulfilling. Maybe I became biased after a few years of maintaining Java EE 8 with Spring and all. Simple readable scripts is the kind of code that reminds me why I enjoy building.