

I have been focused on Site Reliability Engineering (SRE) for the past few years while I have been in EBS. Previously, I was involved in full-stack web developing and architecting web-based services, but I had precious little understanding of this area. Startups building new services probably won’t find a need to invest heavily in monitoring until they have scaled. Established verticals might have little to no SRE because their SLAs may be too loose to warrant significant effort to defend. EBS is a different beast. This service needs to be available continuously for years on end with no downtime, not even from deployments, hardware failures, or network outages. We also need to get the tail of latency down to the point where we are tracking several nines worth of I/O latency outliers (e.g. having more than 99.9999% of I/O occur in less than 100ms is referred to as 100ms outliers above six-nines).
My team faced challenges, and none of us had enough knowledge in this space to find the right solution. At one point, I purchased the O’REILLY Site Reliability Engineering book to learn more about the subject myself. This book focuses on lessons learned from Google running its services at scale. The book is great. I do recommend it for engineers in SRE work. It is nice to go back and reference, full of great ideas to think about. A lot of the information can be found online but sometimes having physical paper to go to makes a world of difference for me. I’m an old fogey like that.
At one point, I scheduled an initial presentation that my entire team attended. I had written a document broadly and succinctly going over key concepts and learnings I wanted my team knowing and thinking about (see Appendix A - SRE 101). This approach was well received and spurred curiosity. My hope was that our ideas around monitoring and alarming work would improve.
SRE is fundamental to maintaining a service that needs to hold itself to standards that customers demand. Services generally need an SLA, a legally binding promise, as a prerequisite to winning over customers. Delivering that promise comes at the cost of monitoring the service and responding to any new event that burns error budget and threatens or breaches an SLO, the internal tighter bars.
With no SLA, customers do not know what to expect and cannot build their business around the service. With no SLO, issues occurring above SLA may not be detected and acted on soon enough since a breach is already too late, already grounds for a lawsuit, or a reason for customers to look for competitors and alternative architecture.
When building alarms, these concepts need to be understood to make correct design decisions. I have seen alarms that were put into effect with no understanding of what their purpose was or how frequently they might go off, leading to dozens of pages per day that turned out to not even be alerting us to anything we did not already know.I have also seen alarms with gaps that major customers could drive their business through all the way to heated calls with leadership since alarm design was divorced from customer experience.
One of the biggest challenges in SRE work I was involved in at EBS was really office politics, for lack of a better word. Whenever there was a perceived gap in alarming, there was ample willpower to fund any development that would enable new alarms to be made. But as soon as the alarms go off, our oncall would find zero actions to take, and the alarm would be ignored. The oncall in EBS performance usually interrupted sleep at least twice a night, sometimes far more. There was little willpower for some time to fund any effort to make alarms actionable, or even to avoid blatant false alarms. We had to get better at selling this effort to leadership that was excessively adverse to customer escalations that had not been caught by alarms. Ironically, we ended up missing things due to distraction from false alarms.
In hindsight, the most important decision we made, in my words, was to “not need to beg forgiveness because the results would speak for themselves”. In Amazon terms, we “Invent and Simplify” to “Deliver Results” by spending time making statistically sound changes to tone down alarms, and fleshing out visibility and tooling to root cause complex issues, we delivered on our charter goals to improve preemptive solving of customer issues. However, we dropped the ball on other top priority efforts coming down from our organization. We did not deliver on every last project. Did we need to beg forgiveness? No. The engineers made the right calls by ignoring engineering decisions coming from leadership, focusing on solving business problems, and delivered more as a result. This is more in line with the desired way AWS intends to function.
This is not to say leadership was poor. This situation was the result of years of past engineering failures in SRE in EBS, most of which I only heard hearsay of. From what I have seen directly, EBS had a history of writing off most performance issues as “probably a network issue or something” because they had no way of tracing down software issues from high-level latency metrics. This eventually leads leadership to design basic and aggressive alarms themselves for engineers to implement.
SRE worked as an amplifier to the rate of innovation driving service performance. The more robust the monitoring and alarming got, the faster the system improves. This also means that SRE work can be difficult to properly value, and the impact of engineers working in SRE can be difficult to measure, since the direct business impact comes from other teams amplified by them.
The most important lesson here to me is to have engineers making engineering decisions based on data that relies on customer needs, and service requirements.
Appendix A - SRE 101
Note this document was written internally at AWS but contains no proprietary information that I would get in too much trouble for sharing. There was some productive conversation in comments on this document in Quip but I need to leave that to the reader’s imagination.
The goal of this document is to be a starting point to help EBS Performance Tools team develop shared agreed upon mental models to guide our decision making around monitoring and alarming.
Next steps: Internal documentation for our team’s monitoring/alarming strategy/mechanisms?
Core SRE concepts
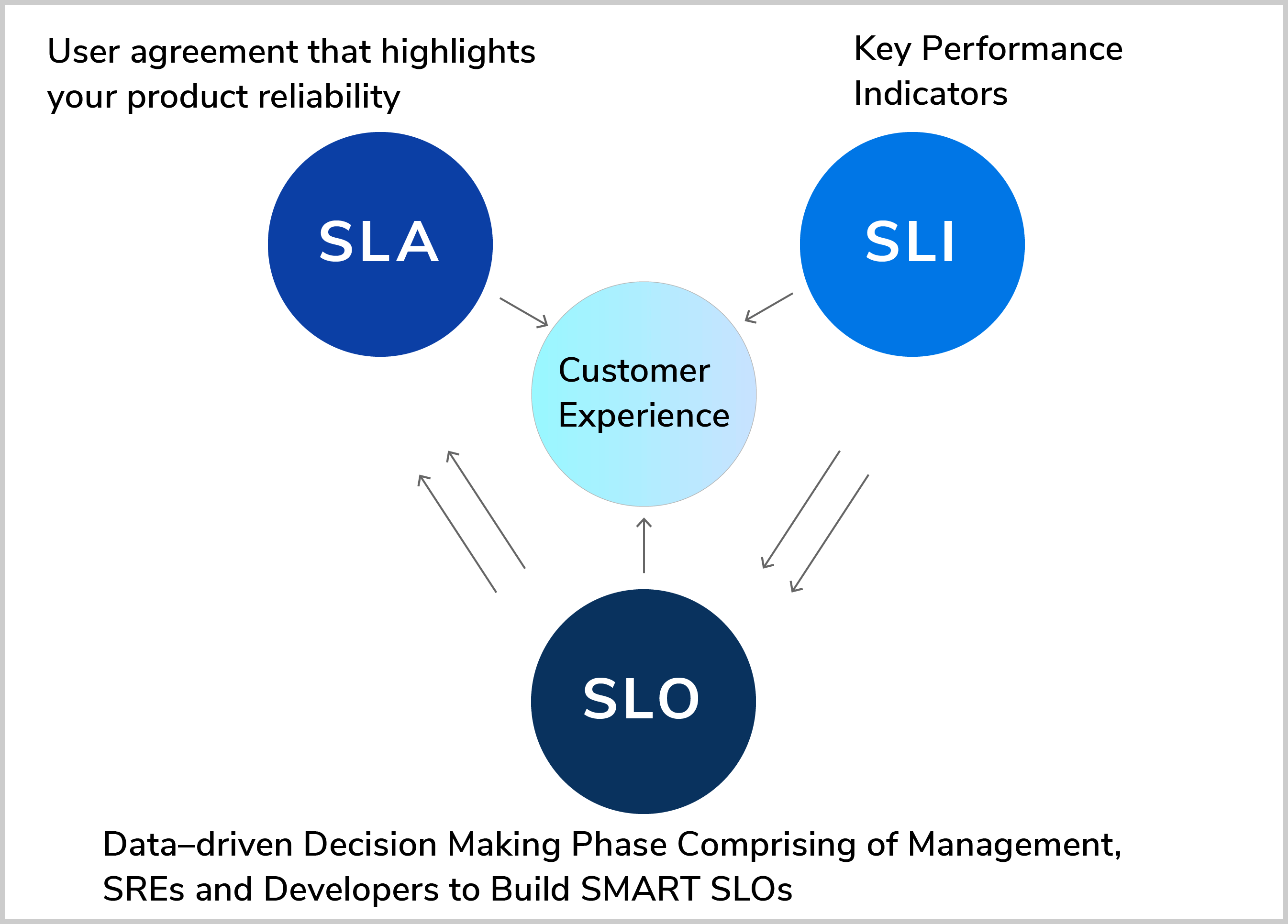
Server-Level Objective/Goal (SLO/SLG) = internal numerical goals, business decision
Service-Level Agreement (SLA) = external numerical goals, promise to customers with consequence, product management decision
Service-Level Indicator (SLI) = direct measurement of service, engineering decision
These are dependencies for monitoring.
Source: https://cloud.google.com/blog/products/devops-sre/sre-fundamentals-sli-vs-slo-vs-sla
Image source: https://dzone.com/articles/the-key-differences-between-sli-slo-and-sla-in-sre
Error budget = customer pain tolerance, how far from 100% metrics can get without harming customer experience
SLI tracks the actual state of the service. SLO is the goal for SLI.
Error budget is the remainder: SLO + Error Budget = 100%.
Source: https://cloud.google.com/blog/products/management-tools/sre-error-budgets-and-maintenance-windows
Understanding SLO/SLI/SLA
Aggregation: Raw measurements are aggregated for simplicity and usability.
Aggregation interval, e.g. “per second” metric implicitly aggregates data over measurement window. This hides bursts.
Averages: Most metrics are distributions rather than averages. Averages hide issues. Percentiles consider shape of distribution. Do not assume data is normally distributed.
Standardize SLIs so you don’t reason about them from first principles every team you create one
-
Aggregation intervals
-
Aggregation regions
-
Measurement frequency
-
Exclusions
-
How the data is acquired
-
Data-access latency
Different services find different SLIs relevant
-
User-facing service: latency, throughput, availability
-
Storage systems: latency, availability, durability
-
Big data systems: throughput, end-to-end latency
All systems care about correctness, i.e. was the right answer returned, the right data retrieved
SLO Guidelines
-
Every SLO contributes to coverage, is simple, and is realistic.
-
If you can’t win a conversation about priorities by quoting a particular SLO, it’s probably not worth having that SLO.
-
SLO < 100%: 100% reduces the rate of innovation and deployment, requires expensive, overly conservative solutions.
-
Don't base target on current performance
-
If you have external SLO, have tighter internal SLO than external SLO to buy error budget.
SLO might look like: lower bound ≤ SLI ≤ upper bound. SLO can be refined over time since it is not a promise.
Defining SLA: SLA is legally binding, hard to change or delete, need product managers and legal. Otherwise SLA is similar to SLO.
Over-reliance: Users incorrectly believe that a service will be more available than it actually is
Under-reliance: Prospective users believe a system is flakier and less reliable than it actually is.
SLO and SLA mitigate over-reliance and under-reliance, as does planned outages or intentional throttling to burn extra excess error budget.
Source: https://sre.google/sre-book/service-level-objectives/
Monitoring
Why we are monitoring
-
Analyzing long-term trends
-
Comparing groups
-
Alerting
-
Building dashboards
-
Ad hoc retrospective analysis i.e. debugging
Four Golden Signals
-
Latency - Time to service a request
-
Traffic - how much demand your system has
-
Errors - Rate of requests that fail
-
Saturation - how full your service is (disk space, memory, throughput). Focus on resources that are most constrained. Latency can be a leading indication of saturation.
Worry about your tail: break up latency into counts of IOs within time ranges instead of averages.
Monitoring Guidelines
-
Monitoring system is exactly as simple as possible
-
Avoid building magic monitoring systems that try to learn or root cause
-
Dependency-reliant monitor rules work well only for very stable parts of system
-
Heavily use white-box monitoring with modest but critical uses of black-box monitoring
White-box monitoring = monitoring based on metrics exposed by internals of system, good for debugging, masked or impending failures
Black-box monitoring = testing visible behavior as users see it, good for alerting humans, symptom-oriented, active problems
Monitoring should be exactly as simple as possible
-
Avoid combining monitoring system with profiling, debugging, testing, determining root cause
-
Rules that catch real incidents most often should be as simple, predictable, and reliable as possible
-
Complexity is for corner-cases
-
Data collection, aggregation, and alerting configuration that is rarely used should be up for removal
-
Signals collected but not used for dashboards or alarms should be up for removal
Source: https://sre.google/sre-book/monitoring-distributed-systems/
Alarming
Alarming Success Metrics
-
Precision - Proportion of events detected that were significant (% of non false alarm auto cuts)
-
Recall - Proportion of significant events detected
-
Detection time - Time between customer impact and ticket/page
-
Reset time - How long alerts fire after an issue is resolved. High reset time means confusion, ignored pain
Types of Alarming Configurations
-
Error rate >= SLO
-
Low precision, high detection time
-
Increased alert window
-
Better precision, worse detection time, very poor reset time
-
Increased alert duration
-
Higher precision, poor recall, poor detection time
-
Alarm on Burn Rate
-
Burn Rate = how fast relative to SLO the service consumes Error Budget
-
Good precision, good detection time, low recall, low reset time
-
Multiple Burn Rates
-
Good precision, good recall, adaptability, complexity, long reset time
-
Multiwindow, Multi-Burn-Rate Alarms
-
Good precision, good recall, flexible, much more complexity to manage
-
Most appropriate technique for defending your SLO
Note for low-traffic services: generate artificial traffic, combine services for monitoring
Source: https://sre.google/workbook/alerting-on-slos/
Pager Guidelines
-
Pages are simple to understand and represent clear failure
-
Pages are infrequent enough so that operator can react urgently
-
Every page is actionable
-
Every page requires intelligence
-
Robotic response required → this alarm should not page
-
Pages are about a novel problem or event
Avoiding false positives
-
All alarms should detect otherwise undetected actionable customer impact
-
Avoid alarms that will be ignored due to being benign
-
Identify cases without customer impact to filter out
-
Make sure the alert is actionable, urgent, cannot be automated right now instead
-
Make sure the correct people get paged
Source: https://sre.google/sre-book/monitoring-distributed-systems/